PostgreSQL Scalability: Strategies for Growing Databases
As PostgreSQL consultants, we have seen firsthand the challenges that come with growing a Postgres database. Whether it’s dealing with increasing data volumes or workload, there are several strategies and approaches to consider when scaling your PostgreSQL database. In this blog post, we will discuss some of these strategies and their pros and cons, as well as relevant pitfalls to be aware of.
Challenges Faced When Scaling a PostgreSQL Database
Increasing Data Volumes
One of the most common challenges faced when scaling a PostgreSQL database is dealing with increasing data size. When starting out with a small database, most of the hot data may fit into RAM. As data volumes grow, first bump in performance will typically happen when the hot data no longer fits into RAM. This will cause more queries will produce disk I/O. This means that more RAM will need to be added to the database server. Soon additional storage needs to be added as well. At some point, the data volumes may outgrow what can be handled by a single server.
Growing Workload
Another challenge faced when scaling a PostgreSQL database is dealing with increasing workload. This typically means an increase in the number of concurrent users or transactions. However, it could also mean that the complexity of the queries increases. Maybe the database was originally used mainly for online transactions but as the business grew, demand for data warehouse and analytics queries grew.
A large number of concurrent transactions can put strain on the database’s resources and affect overall performance. Typically, either RAM will be exhausted by the many concurrent connections or storage I/O will be a limiting factor as disk queues start increasing due to increased need for IOPS. RAM and faster disks may be added but at some point, you will likely reach a limit to how much a single machine can be economically upgraded.
Strategies for Scaling a PostgreSQL Database
Indexing
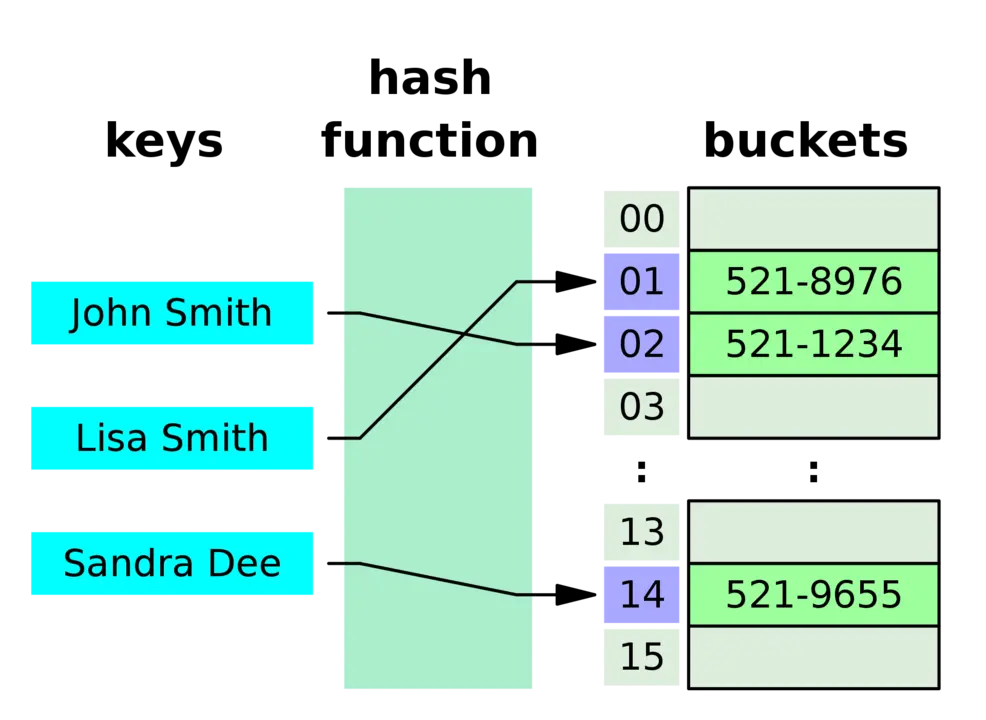
If your database is not properly utilizing indexes, this is typically one of the first low hanging fruits to harvest when scaling a PostgreSQL database.
Indexing involves creating indexes on frequently accessed tables to improve query performance.
This approach is particularly useful when dealing with large tables or complex queries.
Proper indexing has the potential to greatly improve query performance, reduce disk I/O on read queries, and improve resource utilization.
However, indexes comes with a trade-off: They cost additional writes when inserting rows in your tables, and they take up additional disk space. In essence, an index lets you trade a bit write speed and storage space for a significant increase in read speed. As it is common to have tables that are read much more often than written to, this trade-off can very well be a bargain.
Another issue to keep in mind when introducing indexes is maintenance. Indices must be maintained. This involves some amount of housekeeping to avoid index bloat. It is often valuable to have a process to periodically reindex to improve access speed.
Partitioning
Partitioning involves dividing large tables into smaller, more manageable pieces to improve scalability and query performance.
This approach is particularly useful when dealing with very large tables or complex queries.
Advantages of partitioning include improved query performance, reduced disk I/O, and better resource utilization.
However, the advantages come at the cost of increased complexity, and the need for regular maintenance to keep partitions balanced, etc.
Replication
Replication involves creating multiple copies of a database on different servers to improve scalability and availability.
This approach is particularly useful when dealing with high workloads or geographically dispersed users.
For example, a read-only replica may be deployed for clients that do not need to write to the database.
Advantages of replication include improved query performance, increased throughput, improved availability and better fault tolerance.
Replication also means increased complexity and higher operational costs due to more servers being deployed.
Sharding
Sharding is really a type of partitioning in which data is partitioned across multiple database instances to distribute the workload and improve scalability.
Typically, the database is divided and distributed across multiple physical or virtual machines. This approach is particularly useful when dealing with large databases that require high availability and low latency.
The main advantage of sharding is that the load is distributed across multiple machines instead of a single machine. This allows for reduced latency, increased read/write throughput and a more balanced workload. It may also be possible to improve the availability and resiliency of the database with this approach.
Disadvantages of sharding include increased complexity, higher operational costs, and potential data consistency issues if proper thought and care is not given when designing the sharding solution.
Conclusion
Scaling a PostgreSQL database requires careful planning and consideration of the specific challenges faced by your organization. By understanding the pros and cons of each strategy and approach, you can make informed decisions about how to best scale your database while minimizing risks and maximizing performance.
As consultants specializing in PostgreSQL databases, we have experienced the benefits that effective scaling can bring to organizations of all sizes and industries. We have also seen when attempts at scaling have failed and caused services to fail or become unstable.